Introduction
If you operate one or multiple Easticsearch clusters, you probably already heard about disk watermarks. There are three disk watermarks in Elasticsearch: low, high, flood-stage. They are cluster-level settings and are important for shard allocations. Its primary goal is to ensure all the nodes have enough disk space and avoid disk full problems. In this article, we are going to explore their definition, the symptom when the watermark is reached, and different solutions (i.e. how to avoid it in the first place or how to mitigate when it happens).
After reading this article, you will understand:
- How to get and update the watermarks in Elasticsearch?
- Low disk watermark
- High disk watermark
- Flood-stage disk watermark
- How to avoid disk full problem?
- How to go further from here?
This article is written for Elasticsearch 6.x and 7.x. Now, let’s get started!
Overview
Elasticsearch considers the available disk space on a node before deciding whether to allocate new shards to that node or to actively relocate shards away from that node.
Below are the settings that can be configured in the elasticsearch.yml config file or updated
dynamically on a live cluster with the cluster-update-settings API:
| Setting | Description |
|---|---|
cluster.routing.allocation.disk.watermark.low |
The low watermark for disk usage, defaults to 85%. Elasticsearch will not allocate shards to nodes that have more than 85% disk used. |
cluster.routing.allocation.disk.watermark.high |
The high watermark for disk usage, defaults to 90%. Elasticsearch will attempt to relocate shards away from a node whose disk usage is above 90%. |
cluster.routing.allocation.disk.watermark.flood_stage |
The flood-stage watermark for disk usage, defaults to 95%. Elasticsearch enforces a read-only index block (index.blocks.read_only_allow_delete) on every index that has one or more shards allocated on the node, and that has at least one disk exceeding the flood stage. |
To retrieve the current value of different disk watermarks, you can send a GET request to the Cluster Settings API:
GET /_cluster/settings?include_defaults
You may want to add query parameter flat_settings so that you can filter the disk watermarks easily:
GET /_cluster/settings?include_defaults&flat_settings
To update one or more settings of disk watermarks, specify them in the Cluster Update Settings API:
PUT /_cluster/settings
{
"transient": {
"cluster.routing.allocation.disk.watermark.low": "85%",
"cluster.routing.allocation.disk.watermark.high": "90%",
"cluster.routing.allocation.disk.watermark.flood_stage": "95%",
}
}
Now we understand the basics of these settings and how to get and update them. Let’s go further into each of them to better understand their meaning.
Low Disk Watermark
When a data node is getting more and more filled, its disk
usage will first across the low disk watermark. The default value is 85%, meaning that Elasticsearch will not allocate shards to nodes that have more than 85% disk used. It can also be set to an absolute byte value (like 500mb) to prevent Elasticsearch from allocating shards if less than the specified amount of space is available. This setting does not affect the primary shards of newly-created indices but will prevent their replicas from being allocated.
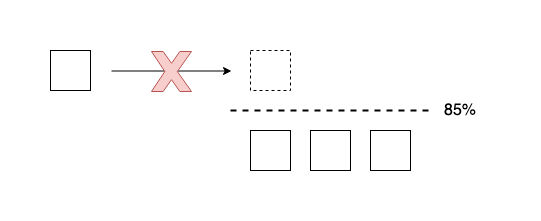
More precisely, you may see the following shard allocation decisions made by the Disk Threshold Decider:
| Decision | Message |
|---|---|
| NO | Shard cannot be allocated because: “the node is above the low watermark cluster setting [cluster.routing.allocation.disk.watermark.low=%s], having less than the minimum required [%s] free space, actual free: [%s]” |
| NO | Shard cannot be allocated because: “the node is above the low watermark cluster setting [cluster.routing.allocation.disk.watermark.low=%s], using more disk space than the maximum allowed [%s%%], actual free: [%s%%]” |
| YES | Shard can be allocated because: “the node is above the low watermark, but less than the high watermark, and this primary shard has never been allocated before” |
Since Elasticsearch cluster will stop allocating shards to this data node, it means that your cluster may become yellow.
There are multiple solutions to solve this:
- Add more data nodes to the cluster.
- Cleanup space by snapshotting old indices, restore them to another cluster if needed, and finally delete them from the current cluster.
- Add more disk on the node.
If you have an auto-scaling mechanism, it means that that auto-scaler is not working properly.
High Disk Watermark
When a data node is getting more and more filled and after reaching the low watermark, its disk usage will across the high disk watermark. The default value is 90%, meaning that Elasticsearch will attempt to relocate shards away from a node whose disk usage is above 90%. It can also be set to an absolute byte value (similarly to the low watermark) to relocate shards away from a node if it has less than the specified amount of free space. This setting affects the allocation of all shards, whether previously allocated or not.
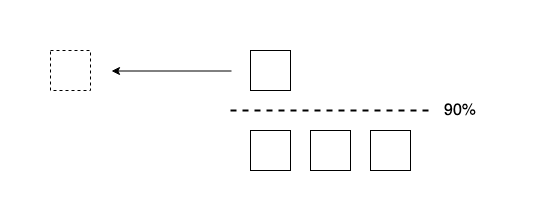
More precisely, you may see the following shard allocation decisions made by the Disk Threshold Decider:
| Decision | Message |
|---|---|
| NO | Shard cannot be allocated because: “the node is above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=%s], having less than the minimum required [%s] free space, actual free: [%s]” |
| NO | Shard cannot be allocated because: “the node is above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=%s], using more disk space than the maximum allowed [%s%%], actual free: [%s%%]” |
| NO | Shard cannot be allocated because: “allocating the shard to this node will bring the node above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=%s] and cause it to have less than the minimum required [%s] of free space (free: [%s], estimated shard size: [%s])” |
| NO | Shard cannot be allocated because: “allocating the shard to this node will bring the node above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=%s] and cause it to use more disk space than the maximum allowed [%s%%] (free space after shard added: [%s%%])” |
| NO | Shard cannot be allocated because: “the shard cannot remain on this node because it is above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=%s] and there is less than the required [%s] free space on node, actual free: [%s]” |
| NO | Shard cannot be allocated because: “the shard cannot remain on this node because it is above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=%s] and there is less than the required [%s%%] free disk on node, actual free: [%s%%]” |
When a data node reached the high watermark, it is usually not alone. The entire cluster can be full. You have to deal with this seriously. In addition to the disk being full, Elasticsearch cluster may create a lot of relocations to relocate shards from one node to another — but it’s useless because all the nodes are getting full.
The solutions for solving this issue are the same as the solutions for the low disk watermark.
Flood-Stage Disk Watermark
The next level is the flood stage. The default value is 95%. Elasticsearch enforces a read-only index block (index.blocks.read_only_allow_delete) on every index that has one or more shards allocated on the node, and that has at least one disk exceeding the flood stage. This setting is the last resort to prevent nodes from running out of disk space. Depending on your Elasticsearch version, the release mechanism is different:
- Before Elasticsearch 7.4, the index block must be released manually when the disk utilization falls below the high watermark.
- Since Elasticsearch 7.4, the index block is automatically released when the disk utilization falls below the high watermark. This is mentioned in the 7.4 breaking changes docs under the Allocation Changes section. Special thanks to Peter Dyson for pointing this out.
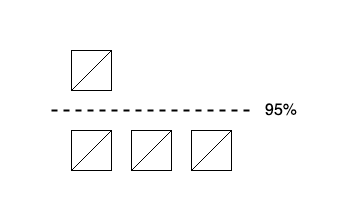
In Elasticsearch 6, since the index block must be released manually, you can reset the index, e.g. twitter, using the following API:
PUT /twitter/_settings
{
"index.blocks.read_only_allow_delete": null
}
How to avoid disk full problem?
Nobody wants to put their production at risk or work on this critical issue at 3:00 AM. This problem can be mitigated in several ways:
- Implement a disk-based auto-scaling mechanism so that new data nodes can be added automatically.
- Create a warning alert for high disk usage, e.g. 50% full. Therefore, developers or operations teams can handle this during business hours.
- Create a critical alert for high disk usage, e.g. 70% full. Therefore, the on-call team can handle this anytime when the situation becomes critical. However, the recovery may take a long time but monitoring this can be tiring as well. You may want to add another disk full alert, e.g. 85% full, to ensure that the situation is not worsened during recovery time.
- Use Elasticsearch Index Lifecycle Management (ILM) to regularly clean up old indices. Or implement a custom index lifecycle management mechanism to adapt your business requirements.
- Use Elasticsearch Snapshot and Restore module so that you can move data easily across clusters.
Going Further
How to go further from here?
- To better understand low disk watermark, visit Opster’s page “Elasticsearch Low Disk Watermark”.
- To better understand high disk watermark, visit Opster’s page “Elasticsearch High Disk Watermark”
- To see how the decisions are made based on different thresholds, see the source code of
DiskThresholdDecider(v7.12.0) on GitHub. - For more information about disk-based shard allocation on Elasticsearch 6, visit official documentation: https://www.elastic.co/guide/en/elasticsearch/reference/6.8/disk-allocator.html
- For more information about disk-based shard allocation on Elasticsearch 7, visit official documentation: https://www.elastic.co/guide/en/elasticsearch/reference/7.12/modules-cluster.html
- To see more shard allocation decisions, visit another article on my blog: “18 Allocation Deciders in Elasticsearch”.
Conclusion
In this article, we saw how different disk watermarks in Elasticsearch: low (85%), high (90%), and flood-stage (95%). All of them are dynamic settings and can be updated without restarting the server. Elasticsearch will not allocate shards to nodes that have more than 85% disk used. Elasticsearch will attempt to relocate shards away from a node whose disk usage is above 90%. A read-only index block will be enforced when the flood stage exceeds. We also see different solutions to avoid disk full problems. Interested to know more? You can subscribe to the feed of my blog, follow me on Twitter or GitHub. Hope you enjoy this article, see you the next time!
References
- Elastic, “Cluster Get Settings API (7.x)”, elastic.co, 2021. https://www.elastic.co/guide/en/elasticsearch/reference/7.x/cluster-get-settings.html
- Elastic, “Cluster-level shard allocation and routing settings”, elastic.co, 2021. https://www.elastic.co/guide/en/elasticsearch/reference/7.12/modules-cluster.html