Introduction
Every chapter has an end and we finally finished the year 2020. 2020 was a difficult year for everyone and COVID-19 changed completely the way we work and live. Many people were infected, some left forever. That’s why I chose a grey image from Kelly Sikkema for this article: to remember the people that were impacted, to remember that life can be challenging, and to thank those who protect us and avoid the situation being worse.
Despite all the difficulties, I am lucky enough to say that 2020 was a good year for me. In this article, I would like to share my technical journey at Datadog as a software engineer working for data storage. Some personal projects I did during my free time, such as open-source project VAVR and this technical blog https://mincong.io. They are not just about what I did, but also some thoughts and lessons learned that I want to share with you. Now, let’s get started!
Datadog
I joined Datadog at the end of 2019 as a software engineer working for the Event Platform. Event Platform ingests trillions of events per day for different products: Logs, APM, Profiling, Real User Monitoring (RUM), Security Analytics, Error Tracking, Network Monitoring, and more. I am mainly working on the storage part, where we host thousands of servers for storing these events. I am really proud of being part of the team. There are many technical challenges to handle and my teammates are very talented. Back in 2019, I wrote an article “Datadog Onboarding Recap”. But now, after working a full year here, I found more interesting points to share with you.
Reliability. Reliability is the key to our backend services. We spent a lot of effort to: ensure service availability, reduce the impact across services when a problem happens, reduce the impact across customers, and ensure that we don’t lose any customer data. This is important for any SaaS application, but I believe it’s even more important for Datadog as a monitoring tool. People usually use Datadog in a critical situation, such as during an incident, so Datadog cannot disappoint them. This year, I contributed to this field in many tasks, such as adding throttling to some services to reduce the impact at peak activity; backing-off client requests when servers are overloaded; participate in the changes of data lifecycle so that we snapshot and restore data continuously and much more.
Observability. When I was a junior developer, I cared a lot about the correctness of the code. But the reality is not just about right and wrong, it’s more complex than that. Many factors can make software not working as expected: the traffic volume, the network conditions, the hardware, the order of execution, the parallelism, the state of the server, etc. Having observability makes it much easier to operate a running system. Talking about observability, we can use metrics, logs, tracing, etc to observe our application and the underlying infrastructure. At Datadog, I learned how to write code with observability in mind. Some basic ideas are: adding a log when the code faces an important event; providing metrics about the application state or resources; adding spans to code blocks to understand and visualize the workflow; measuring the performance with statistics (p50, p90, p95, p99).
On-call. In our platform with 50+ engineers and managers, everyone participates in on-call rotations. No matter you are a software engineer, a team lead, or a director, you need to be part of the rotation. We do that 24/7, i.e. whenever there is a problem in production, at least one person is notified and has to reply in minutes. There is also an escalation policy to ensure we don’t miss any potential problems. This policy is also here to help the primary on-call person for bigger incidents (outages) because one person may not be enough. This year is the first time I participated in the on-call activity. I cannot say that I enjoyed it, that would be a lie. Being paged at 3 AM in the morning trying to fix a problem isn’t fun at all. But globally speaking, it’s worth the effort because it reminds us of the importance of site reliability. If we were paged, it means our customers are having problems — at least a subset of them. It is a great motivation to improve the system and avoid the same problem from happening again.
Multi-language. We use multiple programming languages to build our services. The majority of the Event Platform services are written in Java, but we also use JS for the front-end, Python and Bash for scripting, and Go for the agents. This is a good opportunity to learn other languages, know the advantages and inconveniences of each of them. It also forces us to think about packaging and communication flow between services. For example, we deliver Docker images as artifacts, use RESTful APIs for many exchanges. On my side, I learned a lot about Python this year working on scripting and an internal toolbox for Elasticsearch clusters. I definitely miss the strong typing of Java, but I enjoy using JSON in Python, which is much easier.
OSS
Vavr
Vavr (formerly called Javaslang) is a non-commercial, non-profit object-functional library that runs with Java 8+. It aims to reduce the lines of code and increase code quality. It brings the concept of Scala to the Java ecosystem. After being a member of this project, I contributed several patches to Vavr in 2020:
Vavr-core:
Vavr-jackson:
- #155 Collection serializers and deserializer should be contextual
- #158 Serializer and deserializer of Map and Multimap should be contextual
- #163 Support deserializeNullAsEmpty for maps
- #166 Deserialize classes Option.{Some,None}
You can see the complete list of contributions here for vavr-core and here for vavr-jackson. I also wrote an article for the release note of vavr-jackson 1.0.0 Alpha 3 in https://blog.vavr.io. However, starting from this summer, I lost my interest in continuing the contributions because I don’t have the opportunity to use vavr in Datadog and I don’t see other opportunities to use this library in the mid-term. So I stopped investigating my time on it and tried to put effort into other fields that are more related to my current work.
Algorithm
I have two GitHub repositories about the algorithm and I want to share them with you today.

mincong-h/algorithm-princeton – This project contains my solutions for the Coursera online course: Introduction to Algorithms, created by Princeton University, taught by Kevin Wayne, Senior Lecturer, and Robert Sedgewick, Professor. I created this project when I learned the course back in 2016 and stop maintaining it after. People keep adding stars since then and now reached 90 stars!! I am quite surprised by the popularity of the project but I am happy to see that people love it and find it useful. It makes me understand that hard work gets paid in the end, but you need to be patient to see that day coming. It also encourages me to write software with the quality so that it will still work years after.
AlgoStudyGroup/Leetcode – This project contains solutions of multiple LeetCode challenges starting from Challenge April 2020 to Challenge November 2020. The solutions are written in different languages: C++, C#, Python, Java, Scala, JS, Kotlin. This project was created by Shendan Jin and followed by many other Chinese developers in France when we were bored during the May holidays and the COVID lockdown. It was fun!
Blogging
In 2020, I wrote 28 articles and updated some existing ones. Most of these blog posts are about Java and Elasticsearch. They reflect on what I learned and practiced in my daily work. Here you can see an overview of them, grouped by quarter:

I like writing blog posts because it has several advantages.
- It is a good way to express technology in a human-readable way. Different from writing code, this way is more accessible to most people, even for those that have a little knowledge about the target framework or the language.
- It expresses the motivation and reasoning behind logical choices. Why we need this, why we need that, why shouldn’t we do it in this way, etc. As developers, we need to make decisions every day, it’s important to know the pros and cons, argue the benefits and potential risks face to choices.
- It structures my skills. When writing code, I only know the fraction of the framework I use. Writing articles allow me to take a step back and understand the big picture and other important aspects provided by the product/framework/language.
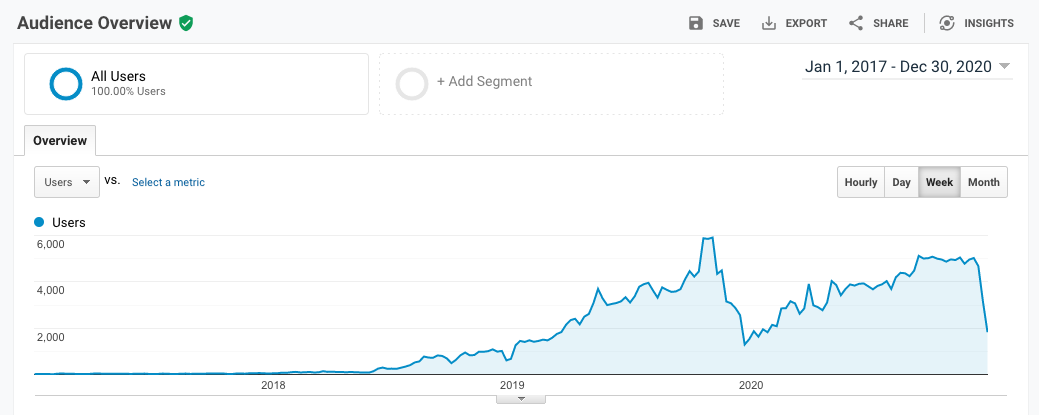
In 2020, I received 234k page views from 182k users all around the world. It’s a 25% increase in terms of page views and a 23% increase in terms of users. Over the 4 years, the traffic grew and dropped, there were a lot of back-and-forths. For example, it dropped significantly end of last year when my article Git: Upstream Tracking Understanding was not featured by Google anymore and when I changed the domain name from https://mincong-h.github.io to https://mincong.io. But overall, the trend is growing up. Back to the 234k page view, it’s such a pleasure to see that my articles are useful for other people! It gives me the motivation to continue writing. Writing for the author himself may just be a daily task, but for readers, it may be the answer for a long-pending problem, a solution for a bug encountered in production, a confusing issue that requires clarification. This reminds me to always go further in my article, find the value points for readers.
Among all the articles written this year, the top 3 articles getting the most page views are:
- Mockito: 3 Ways to Init Mock in JUnit 5 (13,340 page views)
- 3 Ways to Handle Exception In Completable Future (10,031 page views)
- Elasticsearch Scroll API (2,486 page views)
I hope that in 2021, I can share more valuable articles with you!
Conclusion
Thank you for reading this whole article. In this post, I shared some lessons learned from Datadog as a software engineer, open-source contributions at Vavr, and two projects related to Algorithm. Finally, some statistics and thoughts about this blog https://mincong.io. Interested to know more? You can subscribe to the feed of my blog, follow me on Twitter or GitHub. Hope you enjoy this article, see you the next time!