前言
Elasticsearch 的快照与恢复功能是 Elasticsearch 集群的重要组成部分。它的存在为数据可靠性提供了强有力的保障。在这篇文章中,让我们一起看看 Elasticsearch 中官方几个快照插件的相关信息。
在文章正式开始前,让我们先大致地了解一下快照仓库。Elasticsearch 的快照仓库分为本地仓库(local repository)和远程仓库(remote repository)两种。本地仓库主要作为测试使用(单元测试或者试用 Elasticsearch 时使用),在生产线上使用意义不大。生产线上主要使用远程仓库,因为它可以将集群数据放在集群以外的地方,以作为数据备份。官方远程仓库插件主要有:AWS、GCS、Azure、HDFS 四个插件。其中,AWS、GCS、Azure 是笔者这两年经常使用的三个插件,也是这篇文章的讨论主题。
阅读本文后,你会明白:
- 插件的安装与查询
- 快照操作的异同
- 插件与云提供商的依赖关系
- 走进代码:几个有代表性的类的源码分析
- 如何从这篇文章扩展出去
事不宜迟,让我们马上开始吧!
插件的安装与查询
插件可以通过命令行 elasticsearch-plugin 来安装(官方文档):
sudo bin/elasticsearch-plugin install $plugin_name
sudo bin/elasticsearch-plugin install repository-s3
sudo bin/elasticsearch-plugin install repository-gcs
sudo bin/elasticsearch-plugin install repository-azure
sudo bin/elasticsearch-plugin install repository-hdfs
为了让插件能够正常使用,集群的每一个节点都要安装插件。上述四个插件都是 Elasticsearch 的官方插件,无需额外下载,直接安装即可。插件安装成功以后,节点需要重启才能使插件生效。
查询插件的话,有至少两种办法。一是登录节点后,通过命令行查询。二是直接通过 API 查询。
登录节点并通过命令后 elasticsearch-plugin 查询:
sudo bin/elasticsearch-plugin list
无需登录,直接通过 Node API 查询:
GET /_nodes/plugins
快照基本操作
Elasticsearch 的快照操作包括快照仓库管理 API(Snapshot repository management API)和快照管理 API(Snapshot management API)两部分。绝大部分的 API 对于不同插件都是通用的。唯一的例外是创建快照仓库的 API,创建时需要提供仓库的类型。不同仓库的参数也略有不同。这里举几个简单的例子,具体参数可以参考官方文档。
创建 AWS S3 仓库:
PUT _snapshot/my_s3_repository
{
"type": "s3",
"settings": {
"bucket": "my-bucket"
}
}
创建 Google Cloud Storage 仓库:
PUT _snapshot/my_gcs_repository
{
"type": "gcs",
"settings": {
"bucket": "my_bucket",
"client": "my_alternate_client"
}
}
创建 Azure 仓库:
PUT _snapshot/my_backup
{
"type": "azure",
"settings": {
"client": "secondary"
}
}
云提供商依赖关系
使用云提供商相关的插件意味着你必须面对依赖关系的问题。这里的依赖关系主要体现在两部分:云提供商的 SDK 和云提供商的储存系统两方面。
在云提供商的 SDK 方面,由于 Elasticsearch 需要通过云提供商提供的客户端去操作数据(上传、列举、删除等),这里必然存在兼容性的问题。当云提供商的 SDK 版本不断更新的时候,如果你的 Elasticsearch 集群版本保持不变,那么很可能到某个时间点以后 SDK 版本就会过于陈旧无法再使用。使得集群受到无法备份数据的危险。所以及时升级 Elasticsearch 集群版本很重要。
在存储方法,使用特定云服务的储存系统意味着你需要对相应的储存进行配置和管理,比如创建和设置服务账号(service account)等。
走进代码
上面我们主要看了一下比较概括性的信息。在接下来的段落里,我想带大家走进代码,一起来阅读一下几个有代表性的类。
Blob Store Repository
抽象类 BlobStoreRepository 是一个快照仓库的基本实现,它被针对云提供商的 BlobStore 实现所继承。这个类只有两个抽象方法:createBlobStore() 和 basePath()。方法 createBlobStore() 可以用于创建 blob store,而且推荐实现时,采用惰性初始化(lazy initialize)。Blob store 是关于云提供商增删改查在 Elasticsearch 的实现,我们在下文会进一步分析。另一个方法是 basePath,以获得 Elasticsearch snapshot repository 在云提供商储存桶中的相对储存路径。如果是一个储存桶对应一个 repo,那么 base path 应该是 /。如果一个储存桶对应多个 repos 或者一个储存桶有多个用途(不仅用于 Elasticsearch),那么就需要填充一个 Elasticsearch snapshot repo 所在的相对路径。
public abstract class BlobStoreRepository extends AbstractLifecycleComponent implements Repository {
...
/**
* Creates new BlobStore to read and write data.
*/
protected abstract BlobStore createBlobStore() throws Exception;
/**
* Returns base path of the repository
*/
public abstract BlobPath basePath();
}
BlobStoreRepository 是 Elasticsearch 中关于 snapshot 的事务接入点,它实现了 snapshot、restore、get info、delete、cleanup、verify、提取统计数据、更新 cluster state 等功能。
不同的云提供商的 repository 就是继承这个抽象类,并且加入云提供商的 SDK 以实现对于 blob 的读写。从下面的命令行中我们可以看见,无论是只读的 URL Repository,测试用的 Mock Repository,本地仓库的 File System Repository,还是远程仓库 Azure、S3、GCS、HDFS,它们实现都继承了这个类。
➜ elasticsearch git:(7.9 u=) rg "extends BlobStoreRepository"
modules/repository-url/src/main/java/org/elasticsearch/repositories/url/URLRepository.java
56:public class URLRepository extends BlobStoreRepository {
server/src/test/java/org/elasticsearch/snapshots/mockstore/MockEventuallyConsistentRepository.java
68:public class MockEventuallyConsistentRepository extends BlobStoreRepository {
server/src/main/java/org/elasticsearch/repositories/fs/FsRepository.java
53:public class FsRepository extends BlobStoreRepository {
plugins/repository-azure/src/main/java/org/elasticsearch/repositories/azure/AzureRepository.java
55:public class AzureRepository extends BlobStoreRepository {
plugins/repository-s3/src/main/java/org/elasticsearch/repositories/s3/S3Repository.java
72:class S3Repository extends BlobStoreRepository {
plugins/repository-gcs/src/main/java/org/elasticsearch/repositories/gcs/GoogleCloudStorageRepository.java
43:class GoogleCloudStorageRepository extends BlobStoreRepository {
plugins/repository-hdfs/src/main/java/org/elasticsearch/repositories/hdfs/HdfsRepository.java
54:public final class HdfsRepository extends BlobStoreRepository {
Blob Store
Blob store 主要是提供 blobs 相关的两个功能:得到给定路径的 blob container,以及获取对于这个 store 实现的操作的个数统计。一个 snapshot repository 对应一个 blob store。某些云提供商的插件关于 blob 增删改查的逻辑也写在 blob store 的实现里面,比如 Azure 和 GCS 这两个 blob stores 的实现。
/**
* An interface for storing blobs.
*/
public interface BlobStore extends Closeable {
/**
* Get a blob container instance for storing blobs at the given {@link BlobPath}.
*/
BlobContainer blobContainer(BlobPath path);
/**
* Returns statistics on the count of operations that have been performed on this blob store
*/
default Map<String, Long> stats() {
return Collections.emptyMap();
}
}
Blob Container
Blob container 指的是在某路径下的包含所有 blobs 的容器。它不具有 snapshots 相关的逻辑,更偏向底层或者说云提供商那边。它主要负责对于此路径下 blobs 的增删改查的逻辑处理。路径由 BlobPath 表示。以下是它的一些方法:
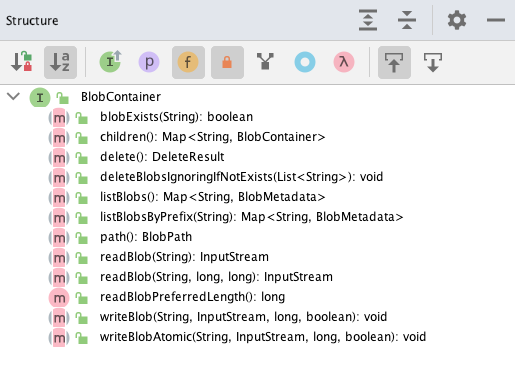
如上文所说,某些云提供商的插件关于 blob 增删改查的逻辑不在此类直接处理,而是委托给 blob store 去处理,比如 Azure 和 GCS 这两个 blob stores 的实现。但是 S3 的逻辑就直接写在类 S3BlobContainer 。所以我感觉它与 Blob container 的界限不是特别清晰。但可以确定的是:一个 repo 里面只有一个 blob store,但一个 repo 可以有好多个 blob containers。
创建快照
下面我们看看,从 BlobStoreRepository 出发,快照是如何创建出来的。这个图是在 IntelliJ IDEA 中,由第三方插件 Sequence Diagram 生成的。为了简化描述,有些步骤被省略。微信中如果图太小不好看,可以点击文末的【阅读原文】转到我的博客或者通过电脑版阅读。
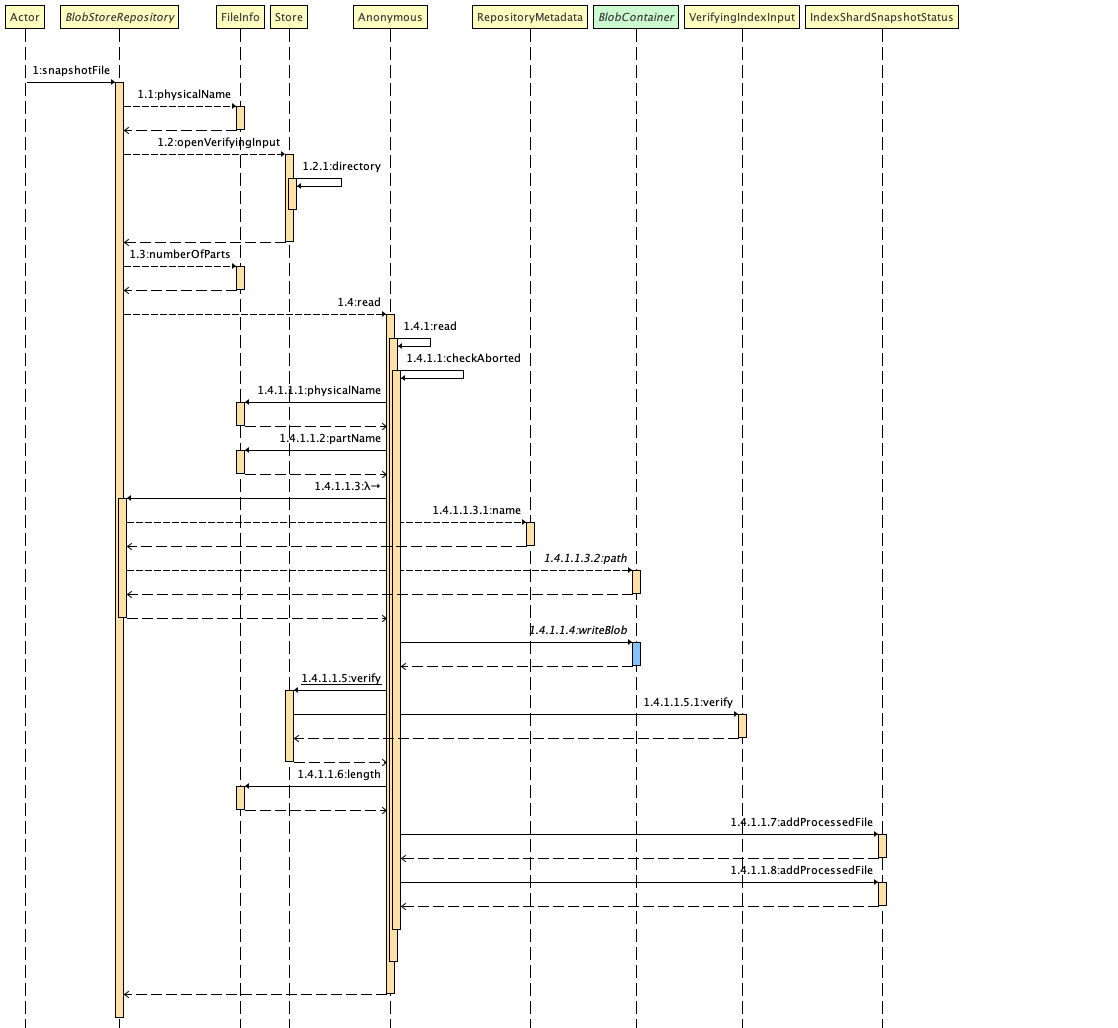
在这个图中我们可以看到,BlobStoreRepository 的方法 snapshotFile 先找到了需要被快照文件的文件名(1.1),然后校验文件的正确性(1.2),然后对于文件的每一个部分(1.3)实现上传。上传时,Elasticsearch 使用了一个自定义的 input stream wrapper 来实现潜在的限流需求(rate limiting)。后面的部分 Sequence Diagram 插件好像凌乱了,它写错了序号。不过瑕不掩瑜,下一步就是写入 blob 了,也就是图中的蓝色部分(1.4.1.1.4)。写入 blob 转交给 BlobContainer 实现。BlobContainer 是一个接口,对应不同的云提供商有不同的实现。实现完成以后,BlobStoreRepository 检查写入数据的正确性。最后,将已经成功实现的快照加入到状态 IndexShardSnapshotStatus 中,用于追踪快照创建进度。
由于时间有限,这篇文章的文章的源码分析大概就讨论到这里吧!
扩展
如何从这篇文章中拓展出去?
- 如果你有兴趣了解 snapshot 仓库内部结构,可以看看我的另一篇文章 Elasticsearch 快照仓库的内部结构
- 如果你有兴趣了解如何防止 Elasticsearch 中的数据丢失,可以看看我的另一篇文章如何防止 Elasticsearch 中的数据丢失?
- 如果想对插件有更多的了解,请查阅官方文档 Elasticsearch Plugins and Integrations
- 如果想对 blob store 有更多的了解,可以在 GitHub 阅读这个 package 的文档和源代码
结论
在本文中,我们看到了如何通过 elasticsearch-plugin 来安装针对不同云提供商的插件;不同插件下,对于快照操作的影响;使用快照插件以后,Elasticsearch 集群与云提供商的依赖关系;接下来,我们走进源代码,简易分析了三个类:Blob Store Repository / Blob Store / Blob Container 的逻辑,并使用创建快照为例子,明白了 Blob Store Repository 是如何和 Blob Container 沟通的。最后,我还和大家分享了一些让从这篇文拓展出去的资源。希望这篇文章能够给你带来一些思考,让你对 Elasticsearch 的快照功能有进一步的了解。如果你有兴趣了解更多的资讯,欢迎关注我的 GitHub 账号 mincong-h 或者微信订阅号【码农小黄】。谢谢大家!