Introduction
The “Snapshot and Restore” feature is an important part of an Elasticsearch cluster. Its existence provides a strong guarantee for data reliability. That’s why we are interested in learning more about it. In this article, let’s take a look at different official snapshot repository plugins in Elasticsearch.
Before getting into details, let’s first understand what is a snapshot repository. There are two types of snapshot repositories: local repository and remote repository. The local repository is mainly used for testing (for unit testing or when trying out Elasticsearch in localhost), and it does not make much sense to use it on production. In production, we mainly use a remote snapshot repository because it can store cluster data outside the cluster as data backup. There are four official plugins: AWS, GCS, Azure, and HDFS. Among them, AWS, GCS, and Azure are the three plugins that I had used in the past two years, and they are also the main subject of discussion today.
After reading this article, you will understand:
- The plugin installation
- The similarities and differences of snapshot operations across different plugins
- The dependency between the Elasticsearch plugin and the cloud provider
- The source code analysis of several representative classes
- How to go further from this article
Now, let’s get started!
Plugin Installation
Plugins can be installed via the command line elasticsearch-plugin (Official Document):
sudo bin/elasticsearch-plugin install $plugin_name
sudo bin/elasticsearch-plugin install repository-s3
sudo bin/elasticsearch-plugin install repository-gcs
sudo bin/elasticsearch-plugin install repository-azure
sudo bin/elasticsearch-plugin install repository-hdfs
For the plugin to be used normally, the plugin must be installed on each node of the cluster. The four plugins mentioned above are all official plugins of Elasticsearch. You don’t need to download them, just install them directly. After a successful installation, the node needs to be restarted for the plugin to take effect.
Once installed, you may want to get information about the plugin. There are at least two ways to query the plugin. One is to query through the command line after logging in to the node. The second is to query directly through the RESTful API.
Log in to the node and list the installed plugins using the following command:
sudo bin/elasticsearch-plugin list
Query the plugins directly through Node API:
GET /_nodes/plugins
Snapshot APIs
Elasticsearch’s snapshot APIs include two parts: Snapshot repository management API (Snapshot repository management API) and Snapshot management API (Snapshot management API). Most of the APIs are common to different plugins. The only exception is the API for creating a snapshot repository. The type of repository needs to be provided when creating it. The parameters for the creation request of different repositories are also slightly different. Here are a few simple examples. If you were interested in any specific parameters, please refer to the official documentation.
Create an AWS S3 repository:
PUT _snapshot/my_s3_repository
{
"type": "s3",
"settings": {
"bucket": "my-bucket"
}
}
Create a Google Cloud Storage (GCS) repository:
PUT _snapshot/my_gcs_repository
{
"type": "gcs",
"settings": {
"bucket": "my_bucket",
"client": "my_alternate_client"
}
}
Create an Azure repository:
PUT _snapshot/my_backup
{
"type": "azure",
"settings": {
"client": "secondary"
}
}
Dependencies With Cloud Provider
Using remote ES snapshot repository plugins means that you have to face the issue of dependencies on your cloud provider. The dependency challenge here is mainly reflected in two parts: the SDK of the cloud provider and the storage system of the cloud provider.
Regarding the cloud provider’s SDK, since Elasticsearch needs to use the SDK client provided by the cloud provider to manipulate data (upload, list, download, delete, etc.), there must be compatibility issues here between the SDK version and your ES cluster. When the SDK version of the cloud provider is constantly updated, if your Elasticsearch cluster version remains the same, the SDK version will likely be too old to be used after a certain point in time. It may make the cluster vulnerable to unsuccessful back-up, downgraded performance, etc. Therefore, it is important to upgrade the Elasticsearch cluster version in time.
In the storage method, using the storage system of a specific cloud service means that you need to configure and manage the corresponding storage, such as creating and setting service accounts.
Source Code Samples
Above we mainly looked at general information about snapshot repository plugins in Elasticsearch. In the following paragraphs, I want to take you into the code and read together a few representative classes.
Blob Store Repository
The abstract class BlobStoreRepository is the base implementation of a
snapshot repository, with works with any blob store implementation.
This class has only two abstract methods: createBlobStore()
and basePath(). The method createBlobStore() can be used to create a blob
store, and it is recommended to implement with lazy initialization. Blob store is
responsible for creating, reading, updating, and deleting data (CRUD) towards to cloud provider
in Elasticsearch. We will analyze it further later. Another method is
basePath(), which obtains the relative storage path of the Elasticsearch
snapshot repository in the storage bucket of the cloud provider. If one bucket
is used for one single repository, then the base path should be /. If one
bucket is used for multiple repositories, or being used for other data-stores
(not only for Elasticsearch), then you need to fill in the relative path where
your Elasticsearch snapshot repo is located.
public abstract class BlobStoreRepository extends AbstractLifecycleComponent implements Repository {
...
/**
* Creates new BlobStore to read and write data.
*/
protected abstract BlobStore createBlobStore() throws Exception;
/**
* Returns base path of the repository
*/
public abstract BlobPath basePath();
}
BlobStoreRepository contains the business logic related to snapshots. It implements functions such as snapshot, restore, get info, delete, cleanup, verify, extract statistics, and update cluster state.
Regardless of the cloud providers, all repositories inherit this abstract class and use the cloud provider’s SDK to implement the blob reading and writing. From the command line below, we can see that whether it is a read-only URL Repository, Mock Repository for testing, File System Repository for local warehouses, or remote warehouses Azure, S3, GCS, HDFS, their implementations all inherit this class:
➜ elasticsearch git:(7.9 u=) rg "extends BlobStoreRepository"
modules/repository-url/src/main/java/org/elasticsearch/repositories/url/URLRepository.java
56:public class URLRepository extends BlobStoreRepository {
server/src/test/java/org/elasticsearch/snapshots/mockstore/MockEventuallyConsistentRepository.java
68: public class MockEventuallyConsistentRepository extends BlobStoreRepository {
server/src/main/java/org/elasticsearch/repositories/fs/FsRepository.java
53:public class FsRepository extends BlobStoreRepository {
plugins/repository-azure/src/main/java/org/elasticsearch/repositories/azure/AzureRepository.java
55:public class AzureRepository extends BlobStoreRepository {
plugins/repository-s3/src/main/java/org/elasticsearch/repositories/s3/S3Repository.java
72:class S3Repository extends BlobStoreRepository {
plugins/repository-gcs/src/main/java/org/elasticsearch/repositories/gcs/GoogleCloudStorageRepository.java
43:class GoogleCloudStorageRepository extends BlobStoreRepository {
plugins/repository-hdfs/src/main/java/org/elasticsearch/repositories/hdfs/HdfsRepository.java
54:public final class HdfsRepository extends BlobStoreRepository {
Blob Store
Blob store mainly provides two functions related to blobs: obtaining the blob container of a given path and obtaining statistics on the count of operations that have been performed on this blob store. For some plugins, the logic of adding, deleting, modifying, and checking blobs is also written in the implementation of blob stores, such as the blob stores Azure and GCS.
/**
* An interface for storing blobs.
*/
public interface BlobStore extends Closeable {
/**
* Get a blob container instance for storing blobs at the given {@link BlobPath}.
*/
BlobContainer blobContainer(BlobPath path);
/**
* Returns statistics on the count of operations that have been performed on this blob store
*/
default Map<String, Long> stats() {
return Collections.emptyMap();
}
}
Blob Container
A blob container refers to the container that contains all blobs under a certain
path. It does not contain logic related to snapshots, but it is more inclined to
the bottom layer of the cloud provider. It is mainly responsible for adding,
deleting, modifying and checking blobs under a given path, represented as
BlobPath. Here are some of its methods:
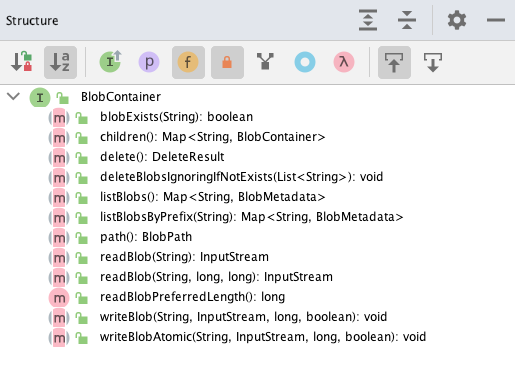
As mentioned in the previous paragraph, for some providers, the logic of adding,
deleting, modifying, and checking blobs are not directly done in this class, but
are delegated to the blob store, like the implementations of Azure and GCS.
However, the CRUD operations of S3 are implemented in the class
S3BlobContainer. So I feel that the boundary between blob store and blob
container is not clear. But one thing is for sure: there is only one blob store in
a repository and a repository may have many blob containers.
Snapshot Creation
Now we understand different classes, let’s take a look at how the snapshot is
created inside a snapshot repository, starting from the class
BlobStoreRepository. The diagram below is generated by the third-party plugin
“Sequence Diagram” in IntelliJ IDEA. To simplify the description, some steps are omitted.
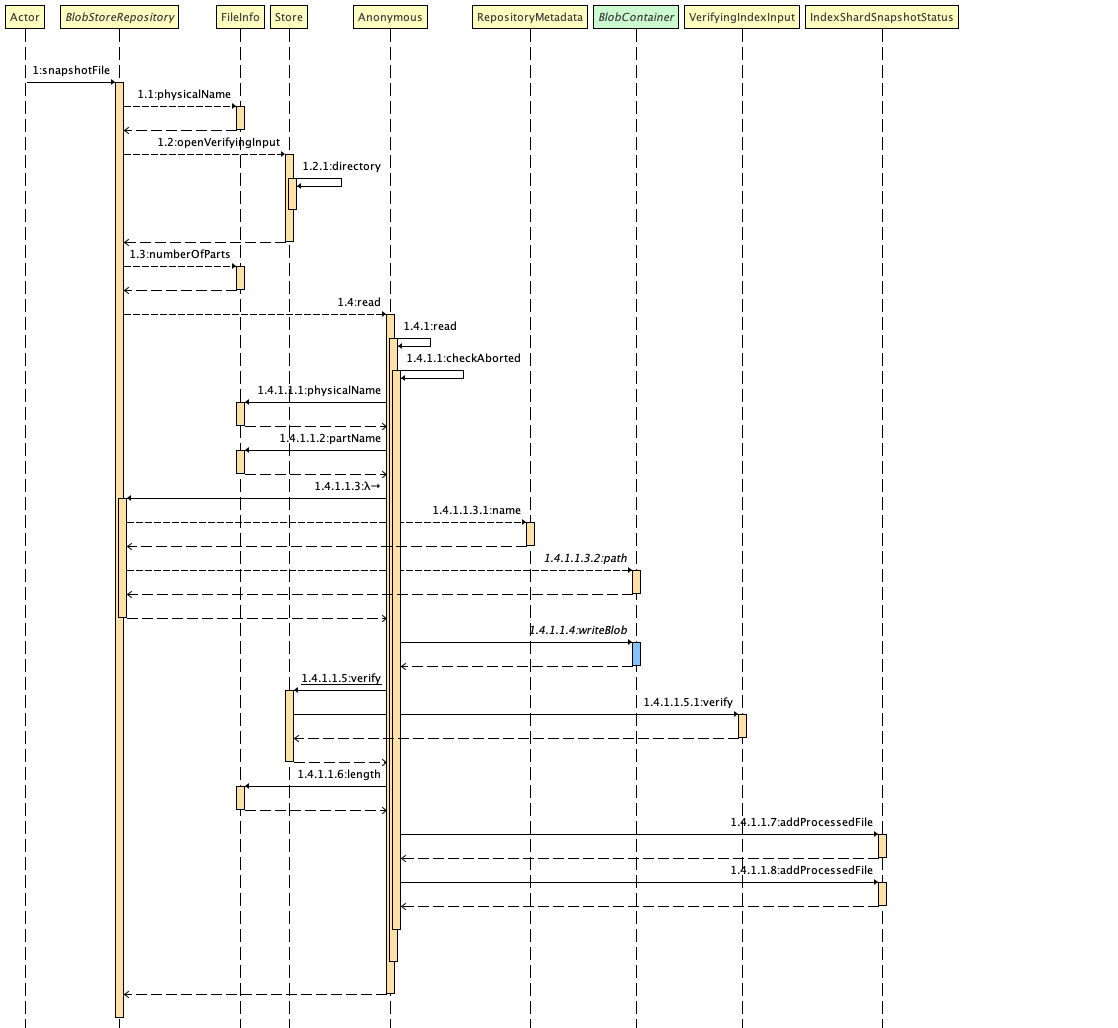
In this figure, we can see that the method snapshotFile of
BlobStoreRepository first finds the file name (1.1) of the file to
snapshot, then verifies the correctness of the file (1.2), and then for each
part of the file (1.3), it performs un upload. When uploading, Elasticsearch uses a
custom input stream wrapper to achieve potential rate-limiting. The latter part
of the Sequence Diagram plugin seems to be incorrect, it writes the wrong serial
number. But the flaws are not concealed, the next step is to write the blob,
which is the blue part in the figure (1.4.1.1.4). Write the blob and forward it
to the BlobContainer implementation. BlobContainer is an interface that has
different implementations depending on the cloud provider. After the
implementation is completed, BlobStoreRepository checks the correctness of the
written data. Finally, the repository adds the successfully created snapshot to the status
IndexShardSnapshotStatus to track the progress of the snapshot creation.
Due to time constraints, we have to stop here for the source code analysis.
Going Further
How to go further from this article?
- If you are interested in understanding the internal structure of the snapshot repository, you can read another article of mine The internal structure of the Elasticsearch snapshot repository
- If you are interested in learning how to prevent data loss in Elasticsearch, you can read my other article How to prevent data loss in Elasticsearch?
- If you want to know more about plugins, please refer to the official documentation Elasticsearch Plugins and Integrations
- If you want to know more about the blob store, you can visit GitHub to read the documentation and source code of this package.
Conclusion
In this article, we saw how to install plugins for different cloud providers
through elasticsearch-plugin; the impact of different plugins on the snapshot
operations; after using the snapshot plugin, the dependency between the
Elasticsearch cluster and the cloud provider; next, we walked into the source
code, briefly analyzed the logic of three classes: Blob Store Repository, Blob
Store, and Blob Container. We also snapshot creation as an example to
understand how Blob Store Repository communicates with Blob Container. Finally,
I also shared some resources to allow you to go further from this article.
I hope this article can give you some thoughts and give you a better understanding of
the “snapshot and restore” feature in Elasticsearch. If you are interested in knowing more
information, you can subscribe to the feed of my blog, follow me on
Twitter or
GitHub. Hope you enjoy this article, see you
the next time!