Introduction
In late 2021, I had the chance to join a new team at Datadog called “Event Platform Automation”, which creates workflows and other types of automation to support the growth of the platform. The goal is to eliminate toil, avoid operational overload, and build packages so that other teams can write their workflows. Since this was a new project, I had the chance to write many things from scratch in Java and Go, and witnessed the growth of the codebase. That’s why I want to write down this article to share my experience with you.
Today’s topic is mainly about complexity. When you start a new project, you will see that the complexity grows a lot. It grows in terms of lines of code, structures, packages, etc. It’s difficult to get it right. And this keeps happening as your business grows (which is a good thing). That’s why I believe it’s worth discussing how to make things done correctly.
After reading this article, you will understand:
- How to manage the complexity in different dimensions?
- Why does continuous refactoring matter?
- What kinds of strategies do you need?
- How to go further from this article?
Now, let’s get started!
Growing in Dimensions
When your codebase grows from 100 lines to 1,000 lines, from 1,000 to 10,000, and even more, you need to find many ways to manage the complexity. Here are some dimensions that it’s worth considering.
Lines of Code
When the project is small enough, the first dimension to consider is to grow the file in terms of lines of code. That is, you just need to add new functions and new structures to express the logic that you want. At this stage, the complexity is not the real concern, the priority may be to get things done and increase the impact of the code.
Files
Once you have more logic, you cannot use the same file all the time. Otherwise, the complexity of that file will explode. That’s how we end up with files having thousands of lines of code and people don’t know how it works anymore. Multiple signals can help you to identify this:
- Multiple developers contributed to your file
- The lines of code increased very fast recently
- We start to see multiple domains or multiple layers in the same file
A straightforward solution is to use multiple files. Each file can represent a domain that you need. For example, when writing a complex workflow, you may need to interact with multiple external services. In that case, you can have one file for each service, where you put all the related logic there.
Classes (Structures)
Most of the time, having functions and files is not enough to support your use cases. This is because we are working with some business logic and many data are related to each other. That’s why you need classes in Java (or structures in Go) to better express your business models and ensure that different pieces of information are consistent. It’s also known as Object-Oriented Programming (OOP).
However, I feel that it’s very easy to abuse the usage of classes and make things confusing. For example, having too many classes that are similar, or having a giant class with too many methods. Face to this problem, there are multiple considerations:
- The lifecycle of the data. If a piece of information is always the same
during a long period or multiple steps of the execution, it makes sense to
add it into a class. Otherwise, if it’s only used for a short period
or one single location, it’s better to put it as a parameter. In Java, I like
making class members
finalso that we can have a clear expectation of the value of that member – we know that it won’t be changed during the whole lifecycle of the instance of the class. - The number of usages of a method. If a method is frequently used, it’s logical to keep it in a class. If a method is only used once or twice and it looks special compared to other methods, perhaps it’s worth moving it to another place: to the caller or another class.
- SOLID principles. Also, consider the SOLID principles: Single responsibility; Open/closed; Liskov Substitution; Interface segregation; Dependency inversion, which helps you to decide what should be put into a single class or separated classes. See also https://www.baeldung.com/solid-principles.
Packages
Once the classes don’t fit your need anymore, perhaps it’s time to consider using packages. Packages are internal libraries that are used for different callers. In the case of workflows, multiple workflows can re-use the same libraries in different manners. We use libraries to interact with different services (GitHub, GitLab, Slack, internal services, etc).
But don’t create a package if it’s not necessary! If you have only one or two files, it does not worth creating a new package. This kind of package is called “shallow modules”. It does not hide many details and is therefore useless for managing complexity. Ideally, the package should be deep, so that it handles complex logic for you and provides simple APIs to make manipulations easy. In the book “A Philosophy of Software Design”, written by John Ousterhout, he mentioned the difference between deep and shallow modules:
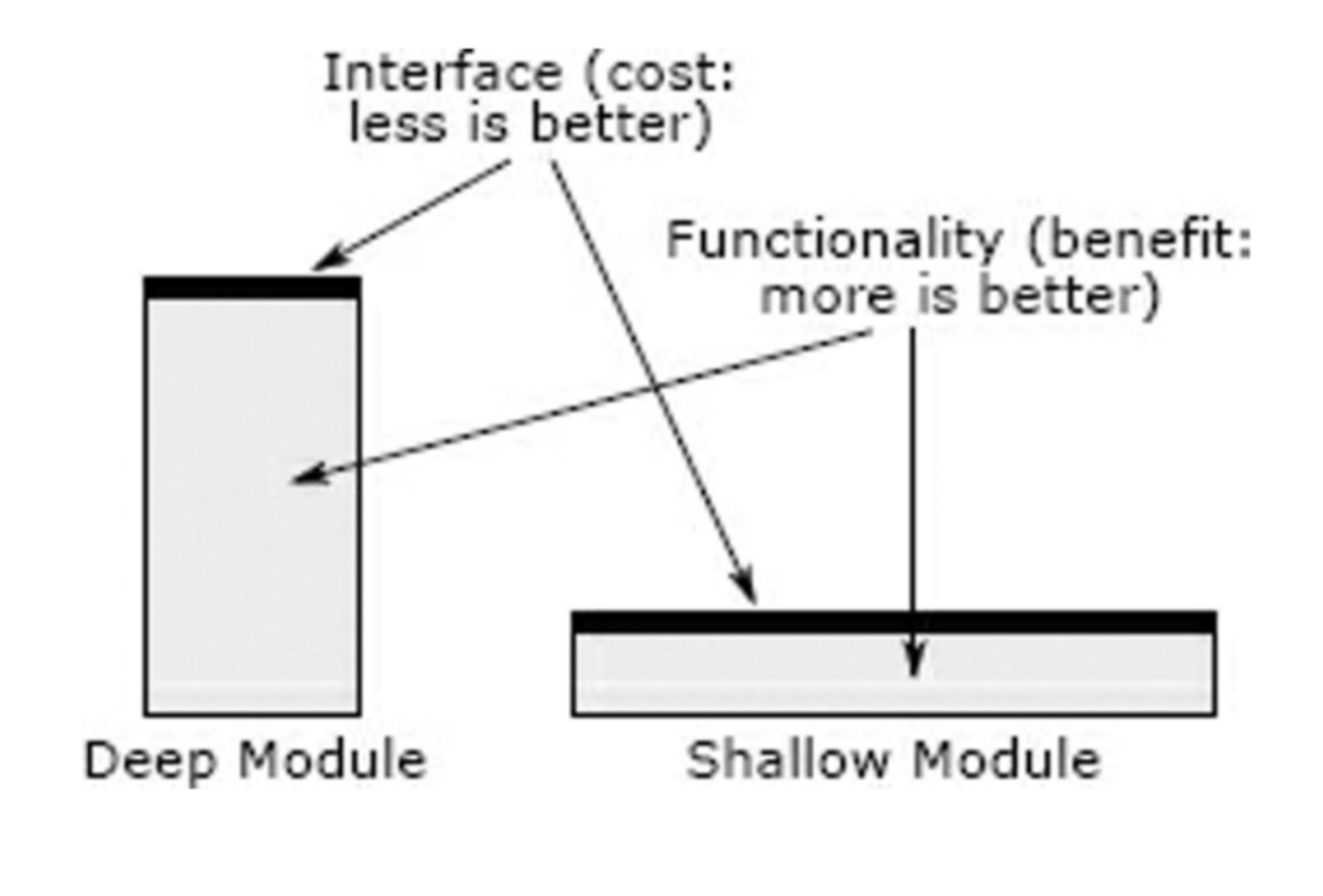
He said: “The best modules are deep: they allow a lot of functionality to be accessed through a simple interface. A shallow module is one with a relatively complex interface, but not much functionality: it doesn’t hide much complexity”.
It’s important to write down some documentation about the package that you are creating. It gives a high-level overview to your readers (the developers that will use the package). It helps people to understand the intention of the package without needing to navigate into the code; the design choices and assumptions that you made during the development.
In my case, I created two packages in Go this year:
- An internal API client to communicate to an administration service via RESTful APIs. In the beginning, it was one method inside a workflow, over time, it becomes an independent file, a shared file used by multiple workflows, and nowadays a library for most of the workflows. It’s built on top of https://pkg.go.dev/net/http and https://pkg.go.dev/encoding/json.
- An internal configuration package, which contains data models to represent different configuration files in Go, deserialized from YAML and Bazel (Starlark). Initially, the package contained only Starlark-related files, but over time, we also need to parse YAML files, and we may welcome other file formats as well.
Layers
Sometimes, having packages is not enough for handling the complexity. You need to have layers. For example, in the API client that I mentioned above, we adapted a two layer architecture, where you can find high-level API clients and low-level API client. Each high-level API client is a virtual API client for a given domain (Kafka, ZooKeeper, Elasticsearch, …) and the low-level client is a virtual for handling acutal HTTP requests, tracing, error handling, etc.

Design Patterns
Now we have multiple domains. It means that there is a high probability that we have similar code in each domain. This causes code duplication. To mitigate the problem, we need to introduce a common structure shared by those structures. This is a skeleton which defines a subset of the logic and allows subclasses to redefine certain steps without changing the algorithm’s structure.
In general, it means using different design patterns to handle the code complexity inside a service: adapter, proxy, factory, composite, builder, decorator, facade, etc.
Services
If you need to grow even further, you can also consider building multiple services. Each service re-uses a subset of the existing packages. In a data platform backend, you can have one service per team or one service per data store.
Continuous Refactoring
If we take a step back, it’s also important to realize that there isn’t any perfect solution that solves all the problems. Therefore, it’s essential to refactor the code continuously and ensure that it fits new use-cases. Here are some aspects of refactoring that I want to mention.
Drawing Diagrams
Drawing diagrams makes the problem more visual. It allows you to better understand what the problem is, communicate with other team members, etc. There are many types of diagrams: flowchat, sequence diagram, class diagram, state diagram, etc. Depending on the requirements, you may use different ones. As for tools, I like using the following ones:
- https://excalidraw.com to draw diagram online
- https://mermaid-js.github.io/mermaid/#/ to write diagram as code, and let the tool to generate the actual result for you.
Testing
Writing tests allows you to have small datasets to validate the behavior of the existing code. It ensures that the refactoring won’t introduce regression to your production (or at least reduce the risk of incidents). There are several moments that you can consider writing tests:
- When developing the software, you can test important cases to ensure the features work as you would expect.
- When someone uses your code and you found bugs, it’s a good moment to enforce the coverage and have more corner cases being covered.
- When it becomes a library, it means that it’s being shared for some people or some projects. It’s also a good moment to improve the coverage.
Generally speaking, testing brings confidence to your refactoring.
Refactoring
Refactoring allows you to adapt the source code for new needs. The typical dimensions are what I mentioned in the previous section: lines of code, files, classes, packages, and services. For example, you may want to:
- use interface to standardize different implementations and define a contract between the users and the maintainers of the library.
- simplify the relationship between some services to make it easier to understand
- creating a class to enforce the consistency between some fields
- avoiding having too much information leaked out to the caller’s side by centralizing them into a single package
These are some very vague ideas. If you need more concrete details about how to do it, I strongly suggest you visit https://refactoring.guru/. It teaches you many design patterns and refactoring skills that you can apply to your daily tasks.
Mindset
Having the right mindset is also important. It allows you to have a clear expectation about what will happen and get prepared for it mentally. Here are some notes that I keep in mind:
- Technical debt always exists. As time goes by, there are always some things that are outdated or unknown to some members. What matters is to control the impact of this technical debt so that it won’t slow you down too much for developing new solutions or maintaining existing ones.
- You need to communicate with your team members. Sometimes people need visibility on what you do. They need to understand why and how will you do it, and also how long will it take. If we have an agreement on what we do, things will move smoothly.
Strategy
How to manage the code complexity efficiently? Here are some strategies that I would consider.
Priority. We need to know what are the most important to address. We need to agree on something as a team, such as, using the OKRs, or finding out what is important for team members. You also need to have support from your manager so that everyone is aligned about the direction.
Data-Driven. Use data to demonstrate what we want to achieve collectively, what are the pain points, what will be the impact, etc. To collect data, you need to think about different dimensions.
Making Assumption. Assume some situations so that we don’t need to care about those cases for now. Perhaps we can address them later on or allow the system to have some imperfections which don’t impact the general mechanism of the solution.
Don’t overthink at the beginning. Focus on what matters most first. That is, it’s OK to take some shortcuts as far as you will come back and refactor later on. This ensures the delivery speed. Done is better than perfect.
Going Further
How to go further from here?
- I recommend the book “A Philosophy of Software Design”, written by John Ousterhout, Stanford University, which shows you the different aspects of software design.
- Visit SOLID Principles to learn more about these 5 principles.
- Visit Refactoring Guru to learn more about different design patterns and refactoring patterns.
Conclusion
Today we discussed how to manage the code complexity in different dimensions, we see how continuous refactoring can help us, and different strategies to allow having an efficient way to spend your time on handling complexity, and finally, some additional resources to go further. Interested to know more? You can subscribe to the feed of my blog, and follow me on Twitter or GitHub. Hope you enjoy this article, see you the next time!