前言
本文是对于在 Medium 平台上由 Netflix Technology Blog 首发的博文 Elasticsearch Indexing Strategy in Asset Management Platform (AMP) 的翻译。原文作者为 Burak Bacioglu 和 Meenakshi Jindal。翻译如有不当之处,欢迎大家在评论区指正,我将尽快修复。
Netflix 的资产管理
在 Netflix,我们所有的数字媒体资产(图像、视频、文本等)都存储在安全的存储层中。我们构建了一个代号为“阿姆斯特丹”的资产管理平台 (AMP),以便轻松组织和管理这些资产的元数据(metadata)、架构(schema)、关系(relations)和权限(permissions)。这个平台还负责资产发现、验证、共享和触发工作流。
阿姆斯特丹服务使用了各种解决方案,例如 Cassandra、Kafka、Zookeeper、EvCache 等。在这篇博客中,我们将重点介绍我们如何利用 Elasticsearch 来索引和搜索资产。
阿姆斯特丹建立在三个存储层之上。
第一层 Cassandra 是我们的真相之源。它由近一百个表(列族)组成,其中大部分是反向索引,以帮助以更优化的方式查询资产。
第二层是 Elasticsearch,用于根据用户查询发现资产。这是我们希望在本文中关注的层。更具体地说,我们会讨论如何在读取密集且持续增长的环境中索引和查询超过 7TB 的数据,并保持我们的 Elasticsearch 集群健康。
最后,我们有一个 Apache Iceberg 层,它以非规范化的方式存储资产,以帮助回答分析用例的繁重查询。
Elasticsearch 集成
Elasticsearch 是最佳且被广泛使用的的分布式开源搜索和分析引擎之一,它适用于所有类型数据,包括文本、数值、地理空间、结构化或非结构化数据。它提供了简单的 API 用于创建索引、索引或搜索文档,使其易于集成。无论您是使用内部部署还是托管解决方案,您都可以快速建立一个 Elasticsearch 集群,并使用基于您的编程语言提供的客户端之一从您的应用程序开始集成它(Elasticsearch 有一组丰富的语言支持:Java、Python、.Net、Ruby、Perl 等)。
集成 Elasticsearch 时的首要决定之一是设计索引、它们的设置和映射。设置(settings)包括索引特定的属性,如分片数、分析器等。映射(mappings)用于定义文档及其字段应该如何存储和索引。您可以为每个字段定义数据类型,或者对未知字段使用动态映射。您可以在 Elasticsearch 网站上找到有关设置和映射的更多信息。
Netflix 内容和工作室工程中的大多数应用程序都处理资产(assets):比如视频、图片、文字等。这些应用都是建立在微服务架构上的,资产管理平台 AMP 为这十几种针对不同资产类型的微服务提供资产管理。平台有一个集中式架构注册服务(schema registry service),专门负责存储资产类型的分类系统(taxonomies)和资产类型之间的关系,每个资产类型都在这个注册服务中被定义。因此,针对每种资产类型创建不同的索引似乎是一件顺理成章的事情。我们也知道,在 Elasticsearch 中创建索引映射时,必须为每个字段定义数据类型。由于不同的资产类型可能具有名称相同但类型不同的字段,而为每种类型设置单独的索引可以防止这样的冲突。于是,我们为每个资产类型各创建了十几个索引,并根据资产类型创建了相应的字段映射。随着更多的应用加入平台,我们不断为新资产类型创建新索引。我们有一个架构管理(schema management)的微服务,用于存储每种资产类型的分类系统(taxonomy)。每当在此服务中有新的资产类型被创建时,新的索引也会被自动创建。对于特定类型的所有资产,它们均使用其专有索引来创建或更新资产文档。

Fig 1. Indices based on Asset Types
由于 Netflix 现在制作的原创作品比几年前我们开始这个项目时要多得多,不仅资产数量急剧增长,而且资产类型的数量也从几十个增加到了几千个。因此,Elasticsearch 索引(每个资产类型)的数量、资产文档索引数量、搜索 RPS(每秒请求数)的数量也随着时间的推移而增长。尽管这种索引策略运行了一段时间很顺利,但有趣的挑战开始出现了。随着时间的推移,我们开始注意到性能问题。我们也开始观察到 CPU 激增、长时间运行的查询、节点状态变为黄色/红色。
译者:那怎么解决这个问题呢?
通常首先要尝试的是通过增加节点数量来横向扩展 Elasticsearch 集群,或者通过升级实例类型来纵向扩展 Elasticsearch 集群。我们尝试了这两种方法,在许多情况下它会有所帮助,但有时这是一个短期修复,一段时间后性能问题又会出现,至少地对我们是这样。所以这也是时候进一步研究,以了解其根本原因了。
是时候退一步,重新评估我们的 Elasticsearch 数据索引和分片策略了。每个索引都分配了固定数量的 6 个分片和 2 个副本(在索引模板中定义)。随着资产类型数量的增加,我们最终拥有大约 900 个索引(即 16200 个分片)。其中一些索引有数百万个文档,而其中许多索引非常小,只有数千个文档。我们发现 CPU 峰值的根本原因是分片大小不平衡。存储这些大分片的 Elasticsearch 节点成为热节点,并且由于线程繁忙,命中这些实例的查询超时或非常慢。
我们改变了索引策略并决定基于时间段而不是资产类型创建索引。这意味着,在 t1 和 t2 之间创建的资产将进入 T1 存储桶,在 t2 和 t3 之间创建的资产将进入 T2 存储桶,依此类推。因此,与其根据资产类型来持久化资产,我们将使用它们的 id(也就是它的创建时间,因为资产 id 是在资产创建时生成的基于时间的 UUID)来确定文档应该持久化到哪个时间段。 Elasticsearch 建议每个分片小于 65GB(AWS 建议小于 50GB),因此我们可以创建基于时间的索引,其中每个索引保存 16-20GB 之间的数据,为数据增长提供一些缓冲。现有资产可以适当地重新分配到这些预先创建的分片,而新资产将始终转到当前索引。一旦当前索引的大小超过某个阈值 (16GB),我们将为下一个存储桶(分钟/小时/天)创建一个新索引,并开始将资产索引到创建的新索引。我们在 Elasticsearch 中创建了一个索引模板,以便新索引始终使用存储在模板中的相同设置和映射。
我们选择在同一个存储桶中索引一个资产的所有版本 - 使用第一个版本所在的那个存储桶。因此,即使新资产永远不会被持久化到旧索引(由于我们基于时间的 id 生成逻辑,它们总是会被转到最新/当前索引),已有资产会在同一个存储桶更新:从而导致在这些旧索引中,仍然有新的文档被创建。因此,我们为滚动选择了一个较低的阈值,这样即使在这些更新之后,旧的分片仍然远低于 50GB。
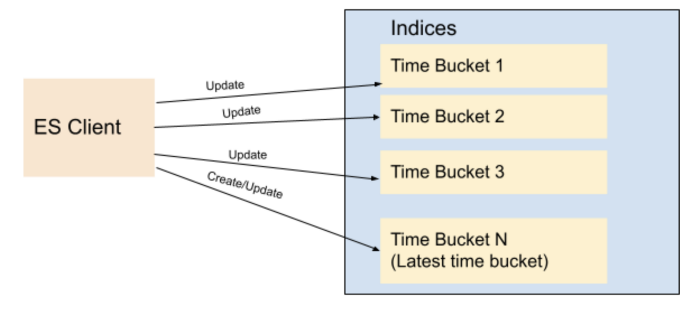
Fig 2. Indices based on Time Buckets
出于搜索目的,我们有一个指向所有创建的索引的读取别名。执行查询时,我们总是在别名上执行它。这确保无论文档在哪里,都将返回与查询匹配的所有文档。但是,对于索引/更新文档,我们不能使用别名,我们使用确切的索引名称来执行索引操作。
为了避免 ES 针对每个索引请求(indexing request)都遍历所有的索引列表,我们将索引列表保存在分布式缓存中。每当为下一个时间桶创建新索引时,我们都会刷新此缓存,以便新资产找到它所对应的索引。对于每个资产索引请求,我们查看缓存以确定资产相应的存储桶。缓存按排序顺序存储所有基于时间的索引(为简单起见,我们根据索引的开始时间以 yyyyMMddHHmmss 格式命名),以便我们可以根据资产创建时间轻松确定应使用哪个索引。如果不使用时间段策略,同一个资产可能会被索引到多个索引中,因为 Elasticsearch doc id 对于每个索引是唯一的,而不是对于集群是唯一的。或者我们必须执行两个 API 调用:首先找到特定索引,然后对该特定索引执行资产更新/删除操作。
如果一个索引发生数百万次更新,那么这个索引仍有可能超过 50GB。为了解决这个问题,我们添加了一个 API,可以以通过程序将旧索引一分为二。为了将给定的桶 T1(存储 t1 和 t2 之间的所有资产)一分为二,我们选择 t1 和 t2 之间的时间 t1.5,并创建一个新的桶 T1_5,然后重新索引在 t1.5 和 t2 之间创建的所有资产,让它们从桶 T1 转移到桶 T1_5。当重新索引发生时,查询/读取仍然由 T1 回答,因此任何创建的新文档(通过资产更新)将被双重写入 T1 和 T1.5,前提是它们的时间戳落在 t1.5 和 t2 之间。最后,一旦重新索引完成,我们启用从 T1_5 读取,停止双重写入并从 T1 删除重新索引的文档。
实际上,Elasticsearch 提供了 Index Rollover 功能来处理日益增长的索引问题。使用此功能,当当前索引大小达到阈值时会创建一个新索引,并且通过写别名(write alias),写入请求将指向刚创建的新索引。这意味着,所有未来的写入请求调用都将转到创建的新索引。但是,这会给我们的更新流程带来问题:因为我们必须查询多个索引以确定哪个索引包含特定文档,以便我们可以正确地更新它。因为我们向 Elasticsearch 的写入请求可能不是按时间顺序的:这意味着在 T1 创建的资产 a1 可能在 T2 创建的另一个资产 a2 被写入 ES 以后才被写入(T2>T1)。这样一来,旧的资产 a1 可能会被储存在新的索引中,而新的资产 a2 则被储存在旧索引中。然而,在我们团队当前的实现中,仅通过查看资产 id(和资产创建时间),我们就可以找出要访问的索引,并且它始终是确定的。(译者:换句话说,也就是使用 Elasticsearch 提供的 Index Rollover 功能无法按照 Netflow 团队的要求实现幂等 idempotence)。
值得一提的是,Elasticsearch 的默认限制是每个索引 1000 个字段。如果我们将所有类型索引到一个索引,我们会不会轻易超过这个数字?那么我们上面提到的数据类型冲突呢?当两种资产类型为同一字段定义不同的数据类型时,对所有数据类型使用单个索引可能会导致冲突。因此,我们改变了我们的映射策略来克服这些问题。我们没有为资产类型中定义的每个元数据字段创建单独的 Elasticsearch 字段,而是创建了一个嵌套类型(nested),其中包含一个名为 “key” 的必填字段以表示资产类型上的字段名称,以及跟数据类型相关的特定字段,例如:string_value、long_value、date_value 等。我们根据值的实际数据类型填充相应的数据类型特定字段(data-type specific field)。您可以在下面看到我们模板中定义的索引映射的节选,以及来自具有四个元数据字段的资产文档的示例:

Fig 3. Snippet of the index mapping

Fig 4. Snippet of nested metadata field on a stored document
正如您在上面看到的,所有资产属性都在同一个嵌套字段元数据 metadata 下,带有一个强制性的 key 字段,以及相应的数据类型特定字段(data-type specific field)。这确保了无论有多少资产类型或属性被索引,我们都只需要在映射中定义固定数量的字段。在搜索这些字段时,我们不是查询单个值(cameraId == 42323243),而是执行嵌套查询,其中我们同时查询键和值(key == cameraId AND long_value == 42323243)。 有关嵌套查询的更多信息,请参阅此链接。
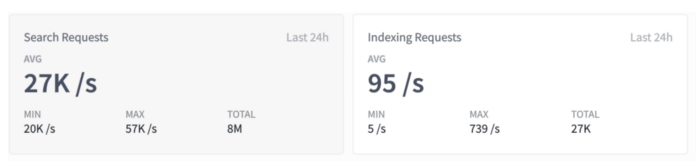
Fig 5. Search/Indexing RPS
在这一系列变化之后,我们创建的索引现在在数据大小方面是平衡的。CPU 使用率从峰值平均 70% 下降到 10%。此外,我们能够将这些索引的刷新间隔时间从我们之前设置的 30 秒减少到 1 秒,以支持先读后写等用例,使用户能够在文档创建一秒后就能搜索并获取它。(译者:下面是新旧架构下的 CPU 使用率比较)
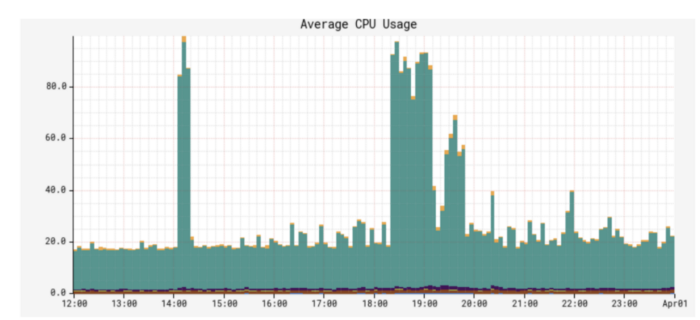
Fig 6. CPU Spike with Old indexing strategy
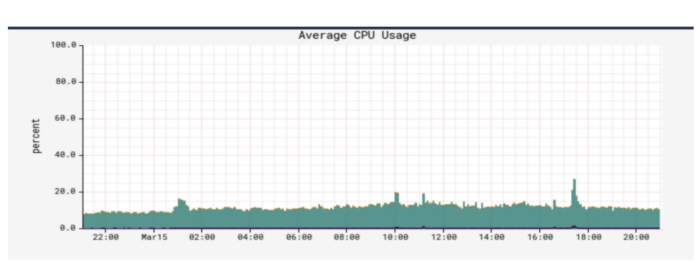
Fig 7. CPU Usage with New indexing strategy
(在使用新的架构之前)我们必须一次性将现有文档迁移到新索引。幸运的是,我们已经有了一个现成的框架,可以从 Cassandra 查询所有资产并在 Elasticsearch 中索引它们。 由于通常不建议在 Cassandra 中对数据量大的表进行全表扫描(可能会超时),我们的 Cassandra schema 包含几个反向索引,可帮助我们有效地查询所有数据。 我们还使用 Kafka 异步处理这些资产,使我们的实时流量不受影响。 这套设施不仅用于将资产索引到 Elasticsearch,还用于对所有或部分资产执行管理操作,例如批量更新资产、扫描/修复它们的问题等。由于我们在本文中只关注 Elasticsearch 索引, 我们计划稍后再写另一篇文章来讨论此套设施。
结论
译者:在本文中,我们看到了 Netflix 的工程师团队对于他们的资产管理平台(AMP)介绍。看到他们多类资产的大数据场景下对于 Elasticsearch 的集成:如何按资产类型设计索引策略、在业务增长后遇到的困难、如何将索引策略改造成按时间建立索引并且保证幂等、如何避开1000个字段的限制、在变更以后性能上的优化,以及这套系统的其他用例。希望这篇文章能够给你带来一些思考,让你的搜索系统变得更高效好用。如果你有兴趣了解更多的资讯,欢迎关注我的 GitHub 账号 mincong-h 或者微信订阅号【码农小黄】。谢谢大家!
参考文献
- Burak Bacioglu and Meenakshi Jindal, “Elasticsearch Indexing Strategy in Asset Management Platform (AMP)”, Medium, 2021. https://netflixtechblog.medium.com/elasticsearch-indexing-strategy-in-asset-management-platform-amp-99332231e541