Introduction
Writing an article for an annual review becomes a tradition for me. After writing it for 5 consecutive years (2016, 2017, 2018, 2019, 2020), I decided to continue this year, to share with you my journey in the tech industry, as a software engineer at Datadog and as an explorer for other side-projects during my free time. Hopefully, they will let you learn something or inspire you to create your story. Now, let’s get started!
Datadog
I joined Datadog at the end of 2019 as a software engineer working for the Event Platform. Event Platform ingests trillions of events per day for 30+ products: Logs, APM, Profiling, Real User Monitoring (RUM), Security Analytics, Error Tracking, Network Monitoring, and more. This year, I kept working on the storage part of the platform, developing new solutions to ensure data reliability, reduce costs, and reduce operational work for other engineers. I was part of the “Event Storage Lifecycle” team and then moved to “Event Platform Automation” team on October. Here are some of my contributions related to these teams.
Why “Event Platform Automation”? Since the platform grew fast, having manual operations became more and more painful. Operating a large-scale system without dedicated operations engineers and site-reliability engineers (SRE) became very challenging. I had the privilege to be part of this team since October 2021. The goals are to improve the system operability at different levels (workflow automation, configuration simplification, automatic checks, admin UI), pushing the reliability to the next level, and improve the deployment process for our microservices.
Indexold. Indexold is a custom solution for data lifecycle management. It is a state machine that manages the lifecycle of the data once they are stored in our system. Similar to Elasticsearch’s Index Lifecycle Management (ILM), it allows moving data from one machine to another. It allows storing historical data in a cost-efficient way, making operations easy, having control about the data placement, and being resilient to node failures. I mainly participated to: storage optimization (data compression), snapshotting, data deletion, rollout to production (AWS, GCP, Azure), and maintenance.
Automation. At Datadog, we use Temporal as a workflow engine for our automation. I made several workflows, such as one for decommissioning Elasticsearch cluster and one for providing checks for the provisioning our pipelines. These workflows contain interactions to other services in the system to read content (GitHub), communicate with the operator (Slack), improve observability (Datadog), or manipulate resources (Kubernetes, Elasticsearch, internal services). This year, I also wrote one article Error Retries in Temporal Workflow and I made my first contribution to Temporal Java SDK (release notes v1.5.0) and hopefully, I can contribute more next year!

Operations. Our operations were mainly to upgrade our data stores (VM at node level, JVM, ES, configuration), deploying to zonal clusters, moving existing data stores from one Kubernetes cluster to another due to capacity constraint, etc. It’s not something very interesting in terms of development but it’s essential to be compliant and keeping the business running.
On-call. According to PagerDuty, I was on-call for 1265h 20m in 2021 (actually I am still on-call when I am writing this article 😅). I handled 228 high-urgency issues in total and 32 of them were incidents. I suspect the total on-call duration is wrong because it may include the Interrupt Handling (IH) work that is also in PagerDuty with much lower priority. But anyway, it provides a sense of how important it is to keep the production running at Datadog. And I am quite proud of it because it’s a collective work and it contributed to the success of the business. Perhaps I will write some articles around how to be on-call since I have some experience in it.
Interviewer. I started the training to become an interviewer in October 2021. I saw many colleagues were doing well on this, so why not try to be part of the team? One major reason that I want to do this is that this YouTube video, I Increased My Productivity 10x - By Turning My Life Into a Game, motivated me to gamify my activities and explore new possibilities, like being an interviewer. I handled 3 shadow interviews so far. My colleagues told me that I lead the exercise and technical aspect of the interview well; selling, behavior, and communication went well; they also appreciated my feedback which gives them detailed and precise information about the candidate. All these made me happy. They also suggested improvement around the time management and explanation around some important details. For me, it’s also a good opportunity to learn what other people are doing as well.
What’s next? In 2022, I would like to own more OKRs to help the team to solve more problems. It probably requires expanding my skill set so that I can implement the solutions from end to end. I would also like to create some opportunities to encourage teamwork because together we can go more further. And finally, I’d like to explore some new areas, such as the read path of Elasticsearch, other data storage systems, or data processing as the upstream of data storage.
Blogging
In 2021, I wrote 42 articles (25 in English and 17 in Chinese). 19 of them are related to Elasticsearch, 7 of them are related to Java, and some posts on other topics like Bash scripting, Nginx, MongoDB, Jekyll, and Javascript. This year I changed the blog theme to Jekyll TeXt Theme and added internationalization support to make the blog more consistent when navigating between English and Chinese blog posts.
Focus on search. Most of these new articles are related to Elasticsearch. For example, there are series “DVF” which demonstrates Elasticsearch’s usage for indexing, storage, search, and analytics using French open dataset for real-estate: “Demande de valeurs foncières (DVF)”; series “Elasticsearch Snapshots” which explores different aspects of the feature “Snapshot And Restore” in Elasticsearch; series “Elasticsearch Cluster Administration” which provides hints for managing Elasticsearch clusters in production. Here are the articles for the DVF series:

Advertising. This year I added the advertising feature for my blog. I wanted to do this because having revenue gives me the motivation to keep writing. I chose EthicalAds because its advertising is transparent for readers: they don’t use cookies to track users, but they match ads based on the content of the site. The ads are relevant to technologies. Currently, I am going to earn about $51.67 (before tax) over the last 2 months and a half.
Audience. 2021 continued to be a great year. More and more people visited my blog. In 2021, I received 294k page views from 222k users, that is a 25% increase in terms of page views and a 21% increase in terms of users. Seeing my articles are useful for other people really motivates me to keep writing.
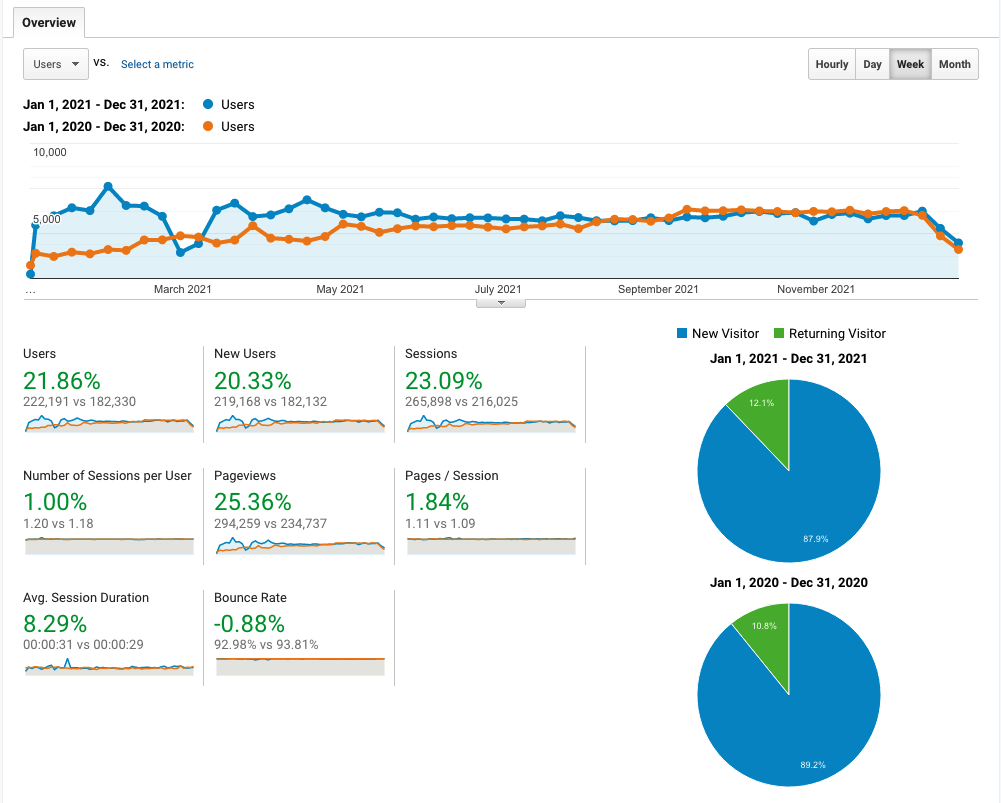
What’s next? In 2022, I would like to continue my focus on data storage because this is my expertise and hopefully they will be valuable for you as well. Then, I would also like to expand the scope to see the bigger picture: performing architecture reviews, translating engineering blogs written by other engineers, writing a series of blog posts, etc. Then it will also be great to increase the publishing cadence because it took me too long to write one article. I want to improve that by introducing a new blog post type: question-and-answer (Q&A), which is a short article containing one question and one answer. Hopefully, it would be possible for readers to subscribe to my mailing list so that I can share the update on a weekly or monthly basis. This should help reduce the bounce rate as well. To summarize, the 4 goals are: keeping the focus on data storage, expanding the scope, improving delivery speed, and attracting more loyal users.
Other Projects
I tried other projects as well. But most of the projects are unsuccessful, but I think it’s still worth sharing why I tried and why it didn’t work.
Vavr (❌). Vavr is an object-functional library that runs with Java 8+. I tried to persuade my teammates to integrate this library in our backend during a hackathon. However, the idea was rejected because the naming of vavr’s types (List, Set, Map, …) are too invasive and therefore conflicting with the standard Java library. So it’s hard to keep both during migration. Also, it’s hard to prove its performance for the critical path (having millions of messages being handled per second). My proposal was rejected. I didn’t see any perspective of using this framework in the short-term or mid-term. Therefore, I decided to stop the contribution and move forwards to something else.
Finance-toolkit (🐢). Finance toolkit is a small library helping you to understand your personal financial situation by extracting, transforming, and aggregating transactions from different companies into a single place: BNP Paribas, Boursorama, Degiro, October, and Revolut. It generates CSV files that can be used for data visualization in Jupyter Notebook. It was created in 2019 and written in Python by Jingwen Zheng and I, with some help from Mickaël Schoentgen. This project still continues at a slow pace.
Sunny (🤔). Sunny Tejiao (阳光特教网) is a non-commercial website that I created last year. It aims to help Chinese teachers working in special education to better gather Chinese-version material for preparing their courses. I did this during my holidays because I feel that there is a lack of Chinese resources in mainland China and it’s hard for teachers to search from the open internet due to government restrictions. I did this also because my mother is a teacher working in a school for special education. Therefore, I feel like it’s a good opportunity for doing so. However, I had to pause the project because my mother didn’t have enough time to help me and she probably had other priorities in her life.
Conclusion
Thank you for reading this whole article. In this post, I shared some projects or important tasks that I did at Datadog as a software engineer, my blogging experience, and some other projects that I explored. Interested to know more? You can subscribe to the feed of my blog, follow me on Twitter or GitHub. Hope you enjoy this article, see you the next time!